Learn MagicTools™ – for PI
Contact us at Believable Magic if you have questions not answered by the learning content found here.
MagicTools is a product of Believable Magic, not of The Predictive Index™ (PI). Please contact PI only if you need help activating API Access or obtaining an API Key for your PI account.
Installation
Table of Contents
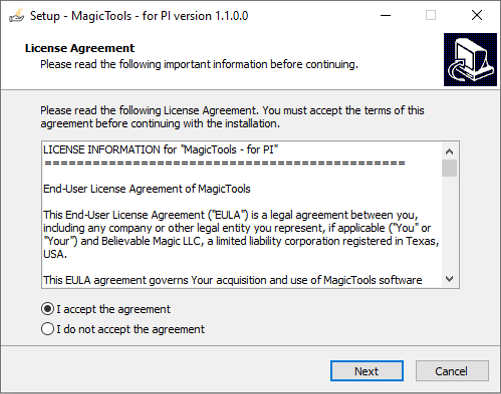
Step-by-step instructions: Installing MagicTools – for PI
Setup Tab
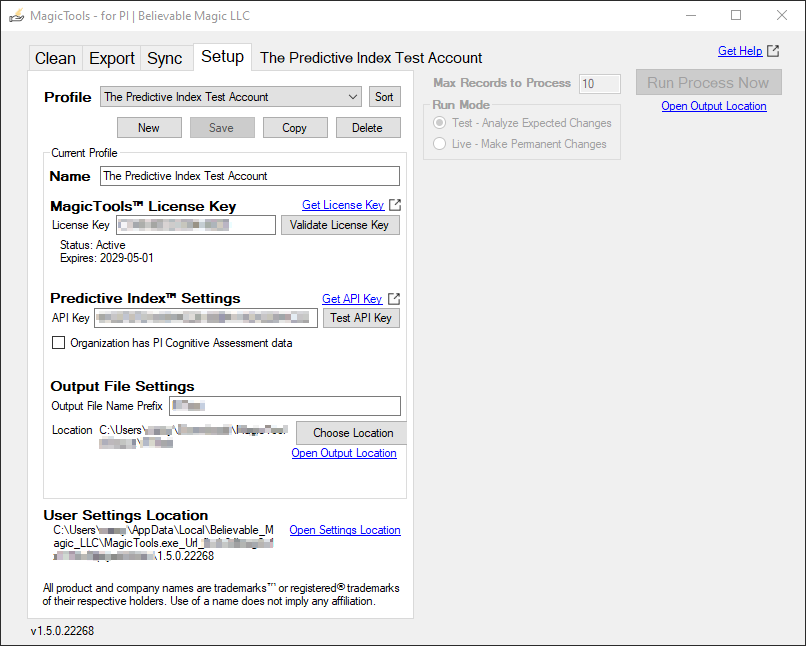
Step-by-step instructions: Configuring MagicTools – for PI via the Setup Tab
General Notes
Internet Required
MagicTools does all of its work over the Internet by connecting to the Predictive Index (PI) Application Programming Interface (API), so if your computer doesn’t have an Internet connection, none of its functions will work until you are reconnected.
Test Mode vs. Live Mode
When MagicTools is processing any action intended to change or archive data, two modes are available: Test and Live.
- In Test Mode, all read-only API calls are made to search for, match, and evaluate which changes should be made, but NO changes are actually made to any data. The output files generated will contain all the predicted outcomes (what would have been changed, what would have been archived).
- You may safely throw away any Test Mode files that you don’t wish to keep because they do not represent real changes.
- In Live Mode, the data is both read and changed according to the action selected. There is NO “undo” available when running in Live Mode — changes are permanent.
- The log files generated will contain all the actual changes that were made to your PI data.
- You should keep the files MagicTools generates when running in Live Mode as a record of what was changed just in case you need to identify some data item that should not have been archived or changed. MagicTools does not offer “undo” features. Any archived PI data becomes invisible via the API and cannot be “un-archived” by any tool such as MagicTools. Any modified PI data can only be changed back again if you use the original pre-modification data to change the data back again. The Predictive Index Support team does not recover archived data, but if you Export your Behavioral Assessment data before using Clean or Sync to archive behavioral assessments, you can use the Behavioral.Assessment.ScoreId to re-create an assessment after it has been archived. All forms of recovery are made much easier if you know exactly what was changed or archived, so keep the log files created in Live mode as a precaution. See also: Archive and Anonymize Defined
Best Practice: Test and Analyze First!
Before you perform the VERY POWERFUL actions on the Clean and Sync tabs using your real “Live” data, it is critically important that you:
- Export any data that might be changed or archived
- Run your intended Clean or Sync process in Test Mode
- Carefully review the processing output report to verify that the right changes are being proposed.
- The output reports are generated as comma-separated text files which means that you should be able to view them in a spreadsheet app like Excel or Google Sheets.
- This review process may involve viewing the individual Persons or Assessments in the PI Software. For this reason, web links leading to the affected PI Person details page within the PI software are included as one column in the processing output file.
- Satisfy yourself that all the changes to your data are correct and that you are willing to archive the data shown in the Test Mode logs. See also: Archive and Anonymize Defined
- Switch to Live Mode and run the process again.
- Note: It usually takes much longer to run in Live Mode.
Stopping a Process
MagicTools does not currently include a feature or button that allows you to stop a process you’ve started before it completes. However, if you change your mind and wish to stop a process, it is “safe” to simply exit the MagicTools software using the X button in the corner of the window at any time, even in the middle of a Live Mode Clean or Sync process.
- The process logs that are recording changes should contain a list of changes actually made at the moment you exited MagicTools.
- All Clean and Sync actions are performed as a series of single changes, so stopping the program in the middle of a process will simply abandon any remaining changes.
- If you re-run a process that you previously stopped in the middle, the software will perform a fresh analysis of the data at that time and then make only the appropriate changes.
Clean Process Tab
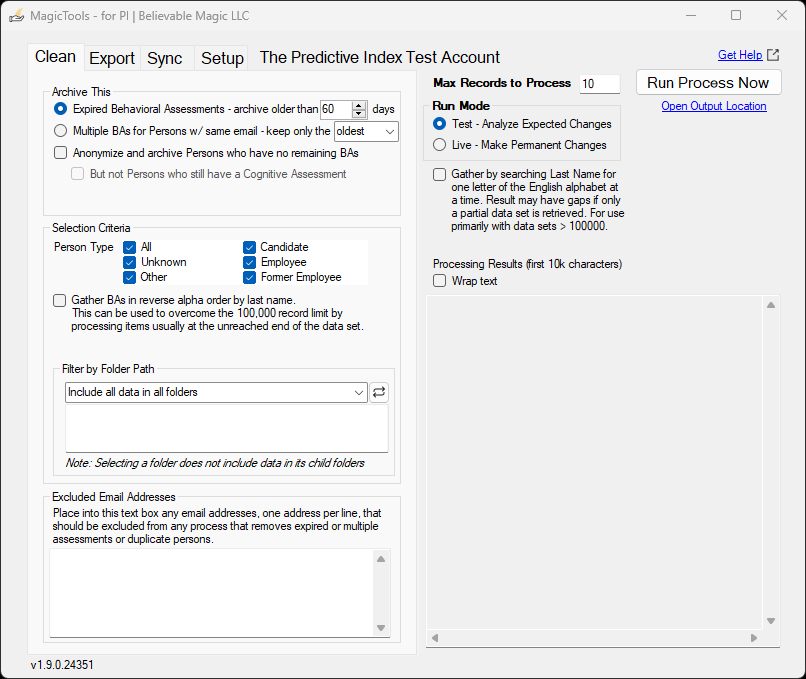
Problem: It is common for any data system, and particularly for assessment systems, to accumulate old, unwanted data over time:
- Incomplete/expired assessments from invitations that were never acted upon
- Multiple complete assessments for the same person
- Duplicate person data representing the same human
All of these unwanted PI persons and assessments make it harder for your users to find good data for a specific person.
Solution: MagicTools Clean aims to reduce this clutter by performing two types of cleaning:
- Remove Expired Assessments and any Persons who only had an expired assessment
- Completed Behavioral Assessments – keep on only the oldest completed assessment and archive all others, removing any Persons no longer needed. See also: Archive and Anonymize Defined
Both of these processes use the same configuration settings:
- Choose which Person Types should be processed (e.g. Candidate, Employee, etc)
- Choose whether to filter the exported data by assessment (Behavioral, Cognitive) and assessment state (Completed, Expired, etc)
- If you are managing a very large PI data collection (more than 100,000 persons with behavioral assessments), there are two features you can use to overcome a 100,000 record limit in the PI API:
- Last Name Initial – One at a time: Gather persons by searching in groups of persons using each letter of the English alphabet so that each letter search can use the full 100K record limit.
- Reverse Alphabetical: Gather persons by searching in alphabetical order or reverse alphabetical order. If you process data in alphabetical order first and then again in reverse alphabetical order, you can reach both ends of the data set and effectively double the number of records reached.
- When processing very large sets of PI data, follow these tips:
- Use “Gather by searching Last Name for one letter of the English alphabet at a time”
- If your data includes a variety of Person Types, run the process completely for each person type separately.
- First, run the process in alphabetical to get the first 100K records.
- Second, run the process in reverse alphabetical order to get the “last” 100K records.
- In this way, you can reach a data set of up to 200K records having Last Name with each letter of the alphabet despite the 100K response size limit.
- Decide whether to filter the exported data by folder. When selecting a specific folder, only the contents of that folder are exported, not the contents of any child folders.
ARCHIVE NOTE: MagicTools Sync also supports removing PI person and assessment data by either using an ArchiveMe column in an input file or by simply archiving all the people found in an input file. See the Sync tab section for more details. See also: Archive and Anonymize Defined.
Expired Behavioral Assessments
This process locates any Behavioral Assessment (BA) that has reached the Expired state. This state is assigned when the expiration date for that assessment has been passed. The expiration date is calculated at the time the assessment was ordered by using the company-wide expiration period setting (a number of days).
This Clean process looks for:
- any Expired BA assessment
- for persons of the chosen Person Type
- that were created more than the selected number of days ago
It archives one expired assessment at a time, then checks whether the Person has any assessment data remaining after archiving it. If the Person has no remaining useful assessment data, the Person is archived also (if the setting is selected to do so). See also: Archive and Anonymize Defined
When NOT to Archive Expired Assessments
- Still Recent and Relevant – If a BA has recently expired, it may relate to a person that is very much interested and involved in the recruiting cycle or another ongoing business purpose. The presence of an Expired assessment could be important information relating to some ongoing processes and outcomes. Archiving an assessment too soon after it has expired may create a confusing situation for your teammates when data they recently created appears to be disappearing.
- Managed by an Automated Integration – An Expired BA can be “re-sent” through features available to a system-to-system integration that uses the Predictive Index API. If you are using such an automated integration, it may be advisable to let your automated integration perform any follow-up on Expired assessments for a period of time. If your automated integration is using the assessmentStatusWebHook feature, that value is not re-used with or copied into subsequent assessments sent for the same person. Keeping and re-using the original assessment is important when relying on an automated integration to follow up on expired assessments. Archiving an assessment using MagicTools puts all of the data linked to that original assessment out of reach of your automated integration.
Note on Re-sending Expired Assessments: Even though the PI software offers the ability to re-send an Expired assessment, such expired assessments are not really used again — the Re-send action in the PI software creates a new assessment and archives the original. MagicTools Clean features cooperate well with PI’s behaviors as long as you are not using an automated integration that relies on the assessmentStatusWebHook, externalId, or externalUserId properties that could be lost when expired assessments are archived.
- If you ARE NOT using an automated integration, archiving expired assessments and persons on a timeline you have chosen only affects the users who log in and view the data and is quite safe.
- If you ARE using an automated integration, check with your integration solution provider before deciding how to use the Clean features of MagicTools.
Best Practice: Archive Only Older Expired Assessments
For the reasons above, the “older than X days” setting is made available so that you can ignore recently Expired assessments and only clean up the older ones that are not recent or relevant. It is wise to start with a larger span of days such as 365 or 180, and then as your processes tighten up and you are confident in doing so, you might run it again with a smaller span of days such as 90 or 60.
Completed BAs – Keep the Oldest or Newest
Research offered by the PI Science team has shown that the first/oldest Behavioral Assessment a person takes is usually the most accurate. However, some PI customers prefer to keep newer Behavioral Assessments. MagicTools Clean offers support for both options.
Problem: Some administrative practices surrounding the BA can lead a candidate or an employee to take and re-take the BA several times over the course of time. For example, an automated integration may not have been designed to avoid duplicates, or the Invite by Link feature of the PI Software may have been used without realizing that duplicated persons and BAs are being created. It is confusing to your users when a person may have many BAs present in your PI data.
Solution: Find all the data for a given person, and remove all the BAs except for the oldest/newest. This is what MagicTools does for you, with a few qualifying considerations. The most reliable method available for identifying multiple PI Persons describing the same human person is to use an email address as the unique identifier. While this may not be perfect due in part to the practice of job applicants using multiple email addresses, it goes a long way to remove known-duplicated data while avoiding making incorrect conclusions using less dependable data such as name. After choosing one BA to keep and the Person associated with it, other additional BAs are archived. If there are any PI Persons left without any remaining assessment data, the Person can be optionally removed as well by checking the box shown in MagicTools. See also: Archive and Anonymize Defined
Considering Cognitive Assessments: If you are using Cognitive Assessments, it is not enough for the cleaning process to examine only the existence of BA data before deciding to archive a Person whose BA assessments have been archived. It is important to keep any Person who has a Cognitive Assessment, even if that Person’s data represents some degree of duplication. The PI platform has no method available to merge Persons, so duplication may be unavoidable if the BA data for a particular human is associated with one PI Person and the Cognitive data is associated with another PI Person for that same human.
Excluded Email Addresses
You might have a collection of persons in your PI data that you do NOT wish to clean/archive — you wish to allow them to retain expired Behavioral assessments or to allow them to have multiple Behavioral assessments.
If this is what you need, simply put the email addresses you wish to exclude/skip into this text area, one email address per line.
The addresses you put into this text area will be saved as part of your current Profile and will be there the next time you run the same process.
Note: When excluding email addresses they are removed AFTER initial record selection. Your process might end up affecting fewer items than the Max Records to Process you selected. For example, if there are two email addresses in your Excluded Email Addresses list found among 20 Max Records to Process, you will get 18 records processed (20 gathered – 2 excluded 2 = 18 processed).
Export Process Tab
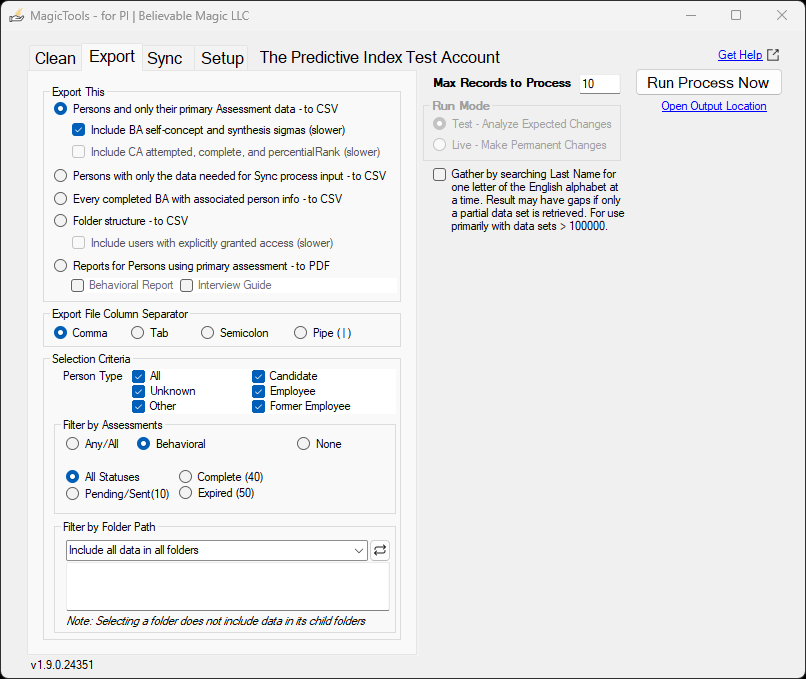
MagicTools Export gives you a way to gather several types of PI data and store it in files on your local computer:
People and only their primary Assessment data – so you can:
- Analyze your PI data to learn new things
- Combine each person’s primary PI assessment data with other data sources to make new connections and gain new insight
- See all your PI person data so you can then use:
- the MagicTools Clean process to remove unwanted data or
- the Sync process to fix the person data
Every completed BA with associated person info – via CSV – so you can:
- See behavioral assessments that are not the default (oldest) assessment included in the People and Assessment export above
- Keep a backup of all behavioral assessments before a Clean or Sync process that might modify or archive some data
Folder structure – to CSV – so you can:
- Review all your current folder structure so you can make plans for a new folder structure into which you plan to move all your person data using Export Person and Sync.
Reports for Persons using primary assessment – to PDF – so you can:
- Obtain and store a PI report as a PDF giving your team access without using the PI software.
Persons and their Assessment data to CSV
Problem: You wish to periodically use PI data in an external system for further analysis, correlation, learning, or reporting, but PI offers reports that may or may not answer the questions on your mind.
Solution: The Export Persons and their Assessment data to CSV option offers the ability to dump into a text file all the person and assessment data you have chosen through the available Selection Criteria.
Optionally, you may wish to include additional data columns, though each of these will significantly increase the amount of time it takes to process:
- Behavioral Assessment individual factor scores for Self-Concept and Synthesis
- Cognitive Assessment number of questions Attempted and Completed, as well as the Percentile Rank
Persons with only the data needed for Sync process input – to CSV
Problem: You wish to update your PI Person data using the MagicTools Sync process (described in the next main section below) but you need to start with the current PI Person data, fix some of it, and then load it back into PI to replace what is in there.
Solution: The Export Persons with only the data needed for Sync process input option offers the ability to dump into a text file only the Person data you can use for the Sync process input. Once you have selected criteria and exported the data, you can use any method you like, manual or automated, to update the data before re-loading it into the PI system using the Sync process.
Note: Because MagicTools includes the PI PersonID (Assessment User ID) in the exported data, the MagicTools Sync process can match any changes made in the exported data to the exact same PI Person.
Every completed BA with associated person info – to CSV
Problem: You wish to update your PI Person data using the MagicTools Sync process (described in the next main section below) but you need to keep a backup copy of the current PI Behavioral Assessment (BA) data in case you want to recover any changed or archived data.
Solution: The Export Every completed BA with associated person info – to CSV option offers the ability to dump into a text file all of the completed Behavioral Assessment data. Once you have selected criteria and exported the data, you can use any method you like, manual or automated, to update the data before re-loading it into the PI system using the Sync process.
Export Separator – select what character should be placed into the output file to separate each “column” of data from the next. Options include: comma, tab, semi-colon (” ; “), and pipe (” | “).
Selection Criteria
Person Type – You can select one or several Person Types:
-
- Unknown
- Other
- Candidate
- Employee
- Former Employee
Filter by Assessments
- Which type of assessment will you use to apply the next criteria?
- Any/All – no filter will be applied based on assessments at all, so you will get all persons.
- Behavioral – filter on the State/Status of the BA. Only persons with a BA will be included.
- Cognitive – filter on the State/Status of the CA. Only persons with a CA will be included.
- None – filter for persons who have neither BA nor CA data. (Persons whose assessments were all archived)
- Which assessment state will you use to select your output data?
- Any/All – ignore assessment state, so include all assessments of the type chosen
- Behavioral – three States/Statuses are available: Pending, Complete, Expired
- Cognitive – five States/Statuses are available: Pending, Complete, Expired, Failed, Aborted
Filter by Folder Path – Select a folder from the drop-down list or enter the full folder hierarchy or “path” including the folder whose data you want to export. For example:
\Your Company Name\Eastern Division\Employees
You can learn more about folder management in the PI Support documentation.
Folder structure to CSV
The Export Folder structure option will gather all the folders names, folder hierarchy, and folder IDs in a your existing folder structure and store them in a text file.
If you select the optional box “Include users with explicitly granted access“, a slower export process will produce two additional columns in the export file, each containing a comma-separated list of First and Last Names of the users:
- UsersWithDirectAccess – these users have been granted access explicitly for the folder named in this row of data
- UsersWithInheritedAccess – these users inherit access to this folder because they were granted explicit access to a parent folder
Note: The user lists shown in the exported data do NOT include any users with roles that automatically have full access to all folders (e.g. Account Owners, Account Admins, or Power Users). Only the users explicitly granted access via the PI > Administration> Folder Management view are included in the export data. Fortunately, only these users shown require manual management when changing permissions.
Problem 1 – Reorganize Folders
You would like to re-organize the folder structure in which all of your PI person and assessment data is stored, but you need a clear picture of the existing structure before you decide what changes to make.
Solution: Using the exported folder data, you can review your existing structure, design a new structure, and then match the old folders to the new folders in a list. Combine your new folder plans with the Person data you get from the the Export Persons with only the data needed for Sync process input option above to change folders for all your existing persons.
Follow these steps to implement a new folder structure:
- Export Folder structure to a file we will call “folder file”
- Open the “folder file” using a spreadsheet program like Excel and add two new columns named something like “Change” and “New Folder Path”.
- In the Change column, put:
“Keep” next to all folders you wish to continue using,
“New” on the row of any additional folders you wish to create, putting the new hierarchy in the New Folder Path column
“Move” next to all the folders you wish to stop using – and in the “move to” folder path in the New Folder Path column - Using the PI software > Administration > Folders, create all the New folders listed in your “folders file” sheet.
- Use MagicTools Export Persons with only the data needed for Sync process input to a file we will call “person file”
- Open the “person file” using a spreadsheet program like Excel and select the FolderPath column
- Use Home > Find and Select > Replace… and perform a find of all Folder Path column values in the “Move” rows using a replace value of the New Folder Path column, then Replace All.
- Repeat the find and replace until all FolderPath values have been changed to their new values
- Use MagicTools Sync in Test Mode with the “person file” as input, un-checking all the columns to be changed except Folder Path — leave it as “Use FolderPath column if valid value present in input”.
- Look at the output file from using Sync in Test Mode. Make any changes as needed.
- Re-run MagicTools Sync in Live Mode
- Use the PI software > Administration > Folders, delete all the Move folders in your “folders file” sheet.
Problem 2 – Manage Folder Permissions
You have a change in staff (hire, replace, terminate) impacting which people should have PI folder access or you are changing the way you grant access to folders for everyone. Rather than hunting through the PI > Administration > Folder Management user interface one folder at at time, you would like to see who has explicit access to which folders so you can focus your attention on only the folders that need updating.
Solution:
- Run the Export Folder structure action and be sure to check the box “Include users with explicitly granted access“. Keep in mind that a large folder structure will take extra time to process.
- In the resulting export data file, you can visually scan for the person you wish to remove or change or use the search features of your spreadsheet program to find the person in question
- While logged into the PI software, go to Administration > Folder Management, expand the folders you wish to correct, and add/remove users as needed. Remember: removing a user from a folder also removes it from the “Inherited” list for child folders.
Reports for Persons to PDF
The Export Reports for Persons option will use your selection criteria to find a list of persons and then save to the Output Folder any of the reports you have chosen as PDF files:
- Behavioral Report – assessment results with the Self, Self-Concept, and Synthesis graphs followed by descriptions of the subject
- Interview Guide – job candidate interview guide for those with a complete Behavioral Assessment and an assigned PI Job
- Cognitive Report – assessment results with a score graph and explanation of the percentile rank
Exported report files are named with the following pattern: LastName_FirstName__ReportType__PIPersonID__ExternalPersonID.pdf
- Last Name
- First Name
- two underscore characters
- Report Type (e.g. PIBehavioralReport, PIInterviewGuide, or PICognitiveReport)
- two underscore characters
- Optional extra info – will be the Job Name in an Interview Guide report
- PI Person ID – internal identifier used by PI software to uniquely identify this person
- two underscore characters
- External Person ID – unique identifier belonging to an ATS or HCM system – may be omitted if not present
Note: Any spaces will be replaced by single underscore characters and any illegal filename characters will be simply removed.
Examples:
- Adams_John__PIBehavioralReport____047aca04-e399-40cc-a7d9-6063b9cb534b__7565241002.pdf
- Adams_John__PIInterviewGuide__Project_Manager__047aca04-e399-40cc-a7d9-6063b9cb534b__7565241002.pdf
- Adams_John__PICognitiveReport____047aca04-e399-40cc-a7d9-6063b9cb534b__7565241002.pdf
A Data file will also be generated that contains a comma-separated (or other separator of your choice) collection of facts about each report generated with the following columns:
- LastName
- FirstName
- ReportType – displayable report type: Behavioral Report, Interview Guide, Cognitive Report
- ExtraInfo – contains the Job Name associated with an Interview Guide; blank for other reports
- PIPersonId – internal PI identifier for the person
- ExternalPersonId – optional, only included if that person has been given a value in the External Person ID field
- ReportFilename – contains the full path and filename for each report file
Sync Process Tab
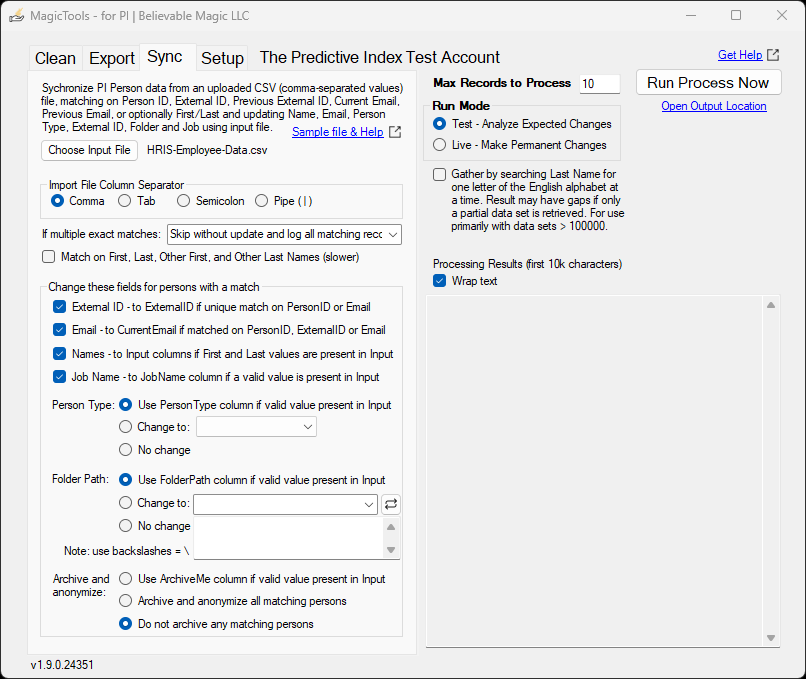
MagicTools for PI will synchronize PI Person data with input from an uploaded Text or CSV (comma-separated values) file by:
- Matching – finding the right person in PI using the Person ID, up to two External IDs, up to two Email Addresses, or optionally First and Last Name
- Updating – making changes to Name, Email, Person Type, External ID, Folder, and/or Job using new values found in the uploaded file or using static Type or Folder values.
- Archiving – anonymizing and archiving persons and their assessments
There are many common problems you might be able to solve by synchronizing your PI data like this.
Common Problems Solved Using Sync
The solutions to the problems below use one of three general approaches to updating your PI data:
Export – Modify – Sync
Start by Exporting current PI data to a file, modifies that data, and then Sync the changed data back into PI. Like this:
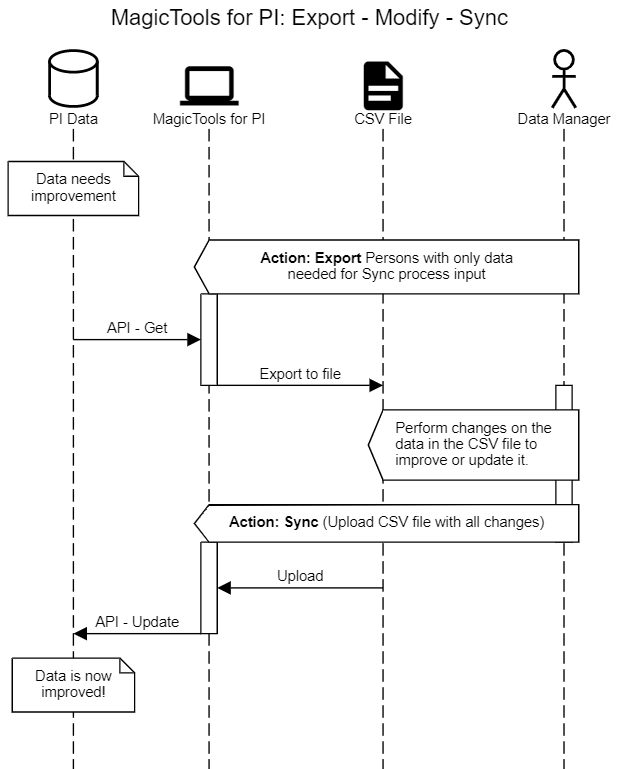
Direct Sync from External File
Start by obtaining a data file from another source such as an HRIS system, make sure the column names match what MagicTools expects, and import it directly.

Combine Two Exported Files and Sync
Start by exporting both PI Data using MagicTools and HRIS Data into two CSV files, then combine the HRIS data into the PI CSV file data, keeping only the matches. Sync this resulting file into PI using MagicTools. Any unmatched persons from the HRIS system must be handled separately.

Problem 1 – Identifying Current Employees Post-Hire
People are added to your PI data during the hiring process using candidate-supplied information, but those who were subsequently hired need to be re-classified as employees and have their PI data updated with their employee info so you can take advantage of the post-hire features of PI. For example, the PI Slack App depends on matching email addresses in both PI and Slack for your team. You need to update several data items:
- Person Type changed to Employee (from Candidate or Other)
- Email updated to use their current (likely employee) address instead of their previous (likely personal) address
- Possibly an external ID changed from a hiring/ATS system ID to an employee/HRIS system ID
- Name updates
- PI Job/position changed to match actual job
- PI Folder path changed from Candidate to Employee
To solve Problem 1, use the Direct Sync from External File method above. Prepare a Sync input file with both a unique data item that identifies each candidate (ATS Candidate ID or Personal Email) from your hiring system and a corresponding data item to identify that person as an employee (HRIS Employee ID or Work Email) from your HRIS system. Also include any changes in name, email, or job name from your employee data. Adjust the column names using the Person Data Upload File guidelines below and the use MagicTools Sync to push the input file into PI.
However, if your HRIS system does not have any candidate identifying data (Candidate ID or Personal Email), then you can use the Combine Two Exported Files and Sync method above. Perform an Export using Magic Tools of all your PI person data, perform an export of your HRIS employee data, and manually combine the HRIS data into the PI person data file placing the HRIS Employee ID into Current External ID, keeping only matches. Then use MagicTools Sync to push the input file into PI.
Problem 2 – Org Upload Collisions with Integration Data
You would like to use the Organization features of PI including uploading a CSV file to PI containing your Org Structure. If you have ever used a hiring/ATS integration with PI that places a candidate or other ID into the externalPersonId field, that ID may be different than the Employee ID needed to make the Org Structure upload work. If you upload your Org Structure without first fixing the externalPersonID to contain the correct Employee ID, the upload process will not recognize the correct persons and will create a new PI person for every employee not successfully matched.
To avoid creating new persons and use the pre-hire PI assessment data for your current employees, you need to update hired candidates’ externalPersonId using their Employee ID so the Org Structure upload process will match all the correct PI persons.
To solve Problem 2, use the Direct Sync from External File method above. Prepare a Sync input file with both a unique data item that identifies each candidate (ATS Candidate ID or Personal Email) from your hiring system and a corresponding data item to identify that person as an employee (HRIS Employee ID or Work Email) from your HRIS system. Also include any changes in name, email, or job name from your employee data. Adjust the column names using the Person Data Upload File guidelines below and the use MagicTools Sync to push the input file into PI.
However, if your HRIS system does not have any candidate identifying data (Candidate ID or Personal Email), then you can use the Combine Two Exported Files and Sync method above. Perform an Export using Magic Tools of all your PI person data, perform an export of your HRIS employee data, and manually combine the HRIS data into the PI person data file placing the HRIS Employee ID into Current External ID, keeping only matches. Then use MagicTools Sync to push the input file into PI.
Then you can use these newly assigned/corrected Employee IDs in an Org Structure upload using the PI software features.
Problem 3 – Org Upload Duplication of Persons without Employee IDs
You would like to use the Organization features of PI including uploading a CSV file to PI containing your Org Structure. However, you have many employees already in PI without an Employee ID in their External ID field. If you use Org Data Upload, you may run into a problem with PI creating new persons for many of your existing employees, sending them an invitation for an assessment when they’ve already taken it.
To solve Problem 3, use the Direct Sync from External File method above. Prepare a Sync input file with both a unique data item that identifies each candidate (ATS Candidate ID or Personal Email) from your hiring system and a corresponding data item to identify that person as an employee (HRIS Employee ID or Work Email) from your HRIS system. Also include any changes in name, email, or job name from your employee data. Adjust the column names using the Person Data Upload File guidelines below and the use MagicTools Sync to push the input file into PI.
However, if your HRIS system does not have any candidate identifying data (Candidate ID or Personal Email), then you can use the Combine Two Exported Files and Sync method above. Perform an Export using Magic Tools of all your PI person data, perform an export of your HRIS employee data, and manually combine the HRIS data into the PI person data file placing the HRIS Employee ID into Current External ID, keeping only matches. Then use MagicTools Sync to push the input file into PI.
Then you can use these newly assigned/corrected Employee IDs in an Org Structure upload using the PI software features.
Problem 4 – Identifying Former Employees
People are represented as Candidates or Employees in your PI data but now some have moved on and should be identified as Former Employees. You may also wish to replace their work email addresses in PI with a personal email address and/or move them out of the Employees folder into a Former Employees Folder.
To solve Problem 4 with an HRIS system, use Direct Sync from External File method above. Generate a data extraction in CSV format from your HRIS system containing all the Former Employees and at least one column used by Sync for matching (Employee ID, Work Email, Personal Email). Use the Sync process column names in place of whatever original column names were generated by the HRIS system.
If you wish to switch your former employees’ email addresses from work email to personal email, then be sure to use CurrentEmail column name for the personal address you want to keep and PreviousEmail column name for their old work email address.
Then use the Sync process with this input file, and set the Person Type setting in the Sync view to FormerEmployee (item in the drop-down list) so that all persons found will be identified as Former Employees.
To solve Problem 4 without an HRIS system, use Export – Modify – Sync method above. Use MagicTools Export to generate a Sync input file with all current PI Employees, then change the Person Type column in that file to FormerEmployee for all those who are no longer employees, and finally, use the MagicTools Sync process to import this updated data file back into PI.
Problem 5 – Changing Employee Data in Bulk
In the past, you were using PI a certain way with your employees and now you want to make a mass change in the data for all your employees. For example:
- Everyone’s email address is changing due to a new domain name after an acquisition
- You’re shifting from position-based email addresses to name-based addresses
- Your PI folder structure is changing and you need to move all your employees into new PI folders at once
- You just created new PI Jobs for many of your common positions and you want to associate many employees with these new jobs
To solve Problem 5, use the Combine Two Exported Files and Sync method above. Use MagicTools Export process to generate a file containing only the Sync input file columns of data, export HRIS data containing the new info you want to use, then use either manual data updates or an Excel VLOOKUP function to match on name, email, or another column with a goal of updating some columns with new values based on the new structure or practices you are moving toward. Then use the MagicTools Sync process with this input file to fix all your PI data at once.
Problem 6 – Cleaning Out Data Selectively
You wish to remove PI data that is no longer needed, but for reasons of your own, you cannot use the anonymization features built into PI and the MagicTools Clean features don’t touch the data you want to remove.
To solve Problem 6, use Export – Modify – Sync method above. Use MagicTools Export process to generate a file containing only the Sync input file columns of data, then use either manual updates to the value of ArchiveMe column (set value to “True”, “Yes”, “T”, or “Y” using any case) or trim the rows of your data file to include only people you wish to archive. Then use the Sync process with this input file to fix all your PI data at once. If you are using the ArchiveMe column, be sure to select that option in the Archive and Anonymize setting. If you wish to archive all persons in the input file, choose the Archive All option. See also: Archive and Anonymize Defined
Person Matching Criteria
The Sync process will only perform changes if one single PI person is found to match any input person row. If none of the searches described below can find a unique person record, the input row will be skipped, the reason reported in the processing output file, and no changes will be made using that row of the input file data.
To find a person, searches will be performed matching up to seven input data file fields with the corresponding five PI person fields. The following logic is followed, in the sequence described below.
Note: Your input file must have a first row containing column names as defined here below or using alternate names for the columns as described in the detailed Person Data Upload File section following this section.
- Input File PersonID = PI Person ID
- The PersonID field is meant to reference an identifier that is “internal” to the PI system. It cannot be changed, but only used to search for an existing PI Person. You can obtain this value in one of two ways:
- By exporting data using MagicTools Export process — there is a PersonID column in the Export output
- By looking at the PI software web address when viewing a person’s detail page — the Person ID shows in the URL after https://app.predictiveindex.com/person/{personId}
- The PI system enforces uniqueness in this field so there is no way that two different PI persons can have the same Person ID.
- If a match is found on this value, no more matching will be performed because it must be the right PI Person record.
- API Note: The PI API refers to this data item using three different names: personId, assessmentUserId, and assessmentUserGuid
- The PersonID field is meant to reference an identifier that is “internal” to the PI system. It cannot be changed, but only used to search for an existing PI Person. You can obtain this value in one of two ways:
- Input File CurrentExternalID = PI External Person ID
- The PI External Person ID field is meant to refer to an identifier that is “external” to the PI system and may or may not be filled in for a particular PI person. If you’ve used the Org Upload feature of PI or an automated integration, PI External Person ID likely contains an Employee ID from a Human Capital Management System or a Candidate ID from a Recruiting System.
- The PI system enforces uniqueness in this field so there is no way to assign the same value to more than one PI person’s External Person ID.
- If a match is found on this value, no more matching will be performed because it must be the right PI Person record. And since the person already has the correct/current External ID, no update to this field will be performed.
- API Note: The PI API refers to this data item as externalPersonId. There is another PI API data item called externalId that refers to an external value associated with a single assessment, not with a single person. MagicTools Sync doesn’t handle the assessment externalId when matching.
- Input File PreviousExternalID = PI External Person ID
- If a match is found using this value, no more matching will be performed.
- If a CurrentExternalID value is included in your input file, the PI External Person ID field will be updated to use that new/current value.
- Input File CurrentEmail = PI Email
- If only one single match is found using this value, no more matching will be performed and that PI person record will be used for any updates. We can assume that the PI Email already contains the correct value.
- API Note: The PI API refers to this data item as email. There is only one email field per PI person.
- Input File PreviousEmail = PI Email
- A search is performed using the PreviousEmail which might be person’s personal email address used prior to being hired or it might be an employee’s work email address used prior to becoming a former employee
- If only one match is found using this email address, we can assume this is the right PI person to update.
- Input File FirstName = PI First Name AND Input File LastName = PI Last Name (optional)
- Finally, a search can be optionally performed by matching the EXACT values of both FirstName and LastName.
- If you wish to use First and Last Name in the matching criteria, check the box labeled “Match on First, Last, Other First, and Other Last Names (slower)”. The matching process is slower when using name matching so this is turned off by default.
- If only one match is found using First and Last Name, we can assume this is the right PI person to update.
- API Note: The PI API refers to these fields as firstName and lastName.
The matching process will give up if none of the above match methods are successful for any single person in the input file. These input records will be skipped and added to a separate Skipped Records File (see Skipped Records File below).
Person Data Input File
Sample Input File: MagicTools-for-PI-Sync-Person-Data-SAMPLE.csv – contains the header row and one sample data row
File Format: Text file with one line/paragraph for each person and column values separated by commas or another separator character
Separators Supported: comma, tab, semicolon (e.g. ” ; “), or pipe (e.g. “|”)
Quotes: If a data element value contains the Separator character, that value must be enclosed in quotes. For example, if the separator character is a comma, the value Company ABC, Inc. must be enclosed in quotes in the CSV file because it contains a comma (e.g. Some Column,”Company ABC, Inc.”, Another Column, etc,etc)
Header Row: The first line/row of the file must contain column names for all data columns included.
- Standard column names: CurrentEmail, PreviousEmail, PersonID, CurrentExternalID, PreviousExternalID, PersonType, FirstName, MiddleName, LastName, OtherFirstName, OtherLastName, FolderPath, JobName, ArchiveMe
- Alternate column names may be used instead of the above names as shown in the Column Header Notes section below.
- The sequence of columns does not matter.
- If more than one column name matches a single defined input column, the first column matching any expected column name will be used and any other matches will be ignored. Example: An input file contains both Email and CurrentEmail columns which are two names for the same input column. If Email appears first in the sequence of columns, it will be used and the CurrentEmail column will be ignored.
- All columns are optional, but any individual row will be processed only if it has a value in at least one of the columns used for matching.
Data Rows: Each row of data must have at least one value in one of the columns used for matching — or it will be skipped. All other columns are optional and may be omitted completely from your file or if included in the header row may contain an empty value. Each line/row must have the correct number of separator characters to match the number of columns named in the first (header) line/row.
Person Data to Include: The sync process will only update PI person data items that are different from the input file data for the person found as a match. You can choose whether to include in your input file only the persons with known changes or to include all your person data regardless of any known changes and let MagicTools skip any rows that don’t require changes.
Note: No “Blanking” of Data: The methods available via the PI API do not support removing a value and leaving that data element “blank” or “empty”. Therefore, it is not possible to store a blank value in the input data file and expect an existing PI value to be removed or filled with nothing. All fields are affected by this limitation. Once any field receives a value, the API cannot be used (and therefore MagicTools – for PI cannot be used) to remove that data field. For example, if a Person already has a value in the JobName column, you cannot use Sync to remove the JobName value, but you can replace it with another existing JobName value.
Special Handling for Removing a MiddleName: PI requires that every PI Person must have a value in the FirstName and LastName fields, but the MiddleName field is optional. When updating name data, the Sync process will update all three fields (First, Middle, and Last) whenever First and Last names are provided in the input file. If the MiddleName field is blank/empty in the input file, but there is a value for Middle Name in the PI data for that person, MagicTools will change the MiddleName to “.”, a period. There is no way to remove the MiddleName field’s content and leave it blank via the API. Since it is still desirable to remove a MiddleName that is known to be wrong, replacing it with a period is the nearest sensible value that carries the equivalent meaning of blank. The only way to update a MiddleName field to an empty value is by logging into the PI software and manually changing the name to blank, and then saving.
Column Header Notes
Case differences and spaces do not matter. The column header names below are also accepted as valid if they contain additional spaces or use any combination of upper, lower, or mixed case (e.g. CurrentEmail = Current Email = currentemail = CURRENT EMAIL)
The sequence of columns does not matter — only the names matter to MagicTools.
PersonID – optional
- Alternate header names: AssessmentUserID, PIPersonID, or ID
- If provided, this will be used first to search for a match before attempting to use CurrentEmail or PreviousEmail for matching
- If no match is found using a PersonID value that was originally exported from your PI data, any matching person found using another match field should be treated with suspicion as an incorrect match.
- The value of PersonID will never be updated since it is impossible to change this value in PI.
CurrentExternalID – optional
- Alternate header names: ExternalID, EmployeeID, ExternalPersonID, CurrExtID CurrentExternalPersonID
- If provided, this will be used second to search for a match before attempting to use CurrentEmail or PreviousEmail for matching
- If no match is found using this value, but a matching person is found using another match field, the PI External Person ID will be updated with this value
PreviousExternalID – optional
- Alternate header names: PreviousID, CandidateID, PreviousExternalPersonID, PrevExtID
- If provided, this will be used third to search for a match after PersonID or CurrentExternalID and before attempting to use CurrentEmail or PreviousEmail for matching
- If no match is found using this value, but a matching person is found using another match field, the PI External Person ID will be updated with this value
CurrentEmail – optional starting with version 1.5.0 — it was REQUIRED in versions prior to 1.5.0
- Alternate header names: Email, NewEmail, EmployeeEmail, EmployerEmail, or WorkEmail
- If provided, this will be used fourth to identify a match after Person ID, Current External ID, Previous External ID and before PreviousEmail are attempted
- If a PI person is found using this email address, no change to their Email data will be made
- If one PI person found using this value, update other fields using any valid data provided; if multiple PI persons match this value, skip this person and perform no update or archive
PreviousEmail – optional
- Alternate header names: OldEmail, CandidateEmail, ApplicantEmail, or PersonalEmail
- If provided, this will be used fifth to identify a match after Person ID, Current External ID, Previous External ID and/or CurrentEmail are attempted
- If a unique PI person is found using this email address, change PI Email to CurrentEmail, then update other fields using any valid data provided
- If multiple PI persons match this value, skip this person and perform no update or archive
PersonType – optional
- Alternate header name: Type, Role
- If provided, matched persons will have their Person Type data updated to the value provided unless a setting is chosen to override this column value
- Acceptable values can be either a name (exact case matters! no spaces allowed!) or the corresponding number:
- Unknown or 1
- Other or 2
- Candidate or 3
- Employee or 4
- FormerEmployee (this value does not have a space!) or 5
FirstName, MiddleName, LastName – optional
- Alternate header names:
- First, FN, GivenName, Given, GN
- Middle, MN
- Last, LN, Surname, Sur, SN
- If both FirstName and LastName are provided in the input data row for a person and the option “Match on First, Last, Other First, and Other Last Names” is checked, these two fields will be used sixth to find a match.
- If both FirstName and LastName are present in an input data row, all three values (including the MiddleName value, even if blank) will be compared to existing data and an update or archive performed on the matching PI person.
- If a PI Person has an existing PI MiddleName but the input file contains a blank MiddleName, the existing name will be replaced by a period “.” because the PI API does not support changing a non-blank field to become blank.
OtherFirstName, OtherLastName – optional
- Alternate header names:
- OtherFirst, PrevFirst, PreviousFirstName
- OtherLast, PrevLast, PreviousLastName
- If either of these names are provided and the option “Match on First, Last, Other First, and Other Last Names” is checked, any non-empty names will be combined with the sixth matching step described above. All non-empty Other names will be checked to find all possible matches: First + Last, First + Other Last, Other First + Last, and Other First + Other Last.
FolderPath – optional
- Alternate header names: Folder, or PIFolder
- Must be a valid PI Folder path including single or double backslashes, like this (and quotes around any fields with the file delimiter):
- \XYZ Company\Western Division\Employees
- \\XYZ Company\\Western Division\\Employees
- “\XYZ Company, Inc.\Western Division\Employees”
- If no PI Folder Path with this exact value exists, skip this person without any updates
JobName – optional
- Alternate header names: Job, PIJob, PRO, or JobProfile
- Must be a valid PI Job name
- If no PI Job with this exact name exists, skip this person without any updates
ArchiveMe – optional
- Alternate header names: Archive, Purge, Delete
- Any of the following values will be translated to mean the record SHOULD be archived: “Yes”, “True”, “Y”, “T”, “Archive”, “Delete”, “Arch”, “Del”, “A”, “D”, and the case does not matter.
- Any other value or blank will be translated to mean the record SHOULD NOT be archived.
- Archive and anonymize this person and archive all their assessments. By “anonymize” we mean that any personal data items (names, email, person type) are replaced with meaningless values before the data is archived, thereby making it impossible to recover that data and identify it with a person. See also: Archive and Anonymize Defined.
Working with the Sync Process
Sync: Step-by-Step
- Construct an Input File containing all the data you want to have stored in PI for the persons you’ve included, following the detailed instructions above.
- Choose Input File – Save that file in a location accessible from the MagicTools software and select it using Choose Input File button.
- Decide how to handle multiple matches:
- Skip without update and log number of matches – no change will be made and the Log file and Skipped file will only contain a number of matches that were found
- Skip without update and log all matching records (default) – no change will be made, the Log file will contain a number of matches that were found, but the separate Skipped file will contain an additional row containing a few fields describing all matching PI person data records, one match per row.
- Update all matching records – for all matching persons, perform a full update of the PI person data from the single row of the input file. WARNING: This should only be done if you are certain you wish to end up with multiple persons in the PI data with the same identifying information (Name, Email, PersonType, Folder, etc) as selected in the Input file or the settings below. It is NOT advisable to use this option when matching based on Names.
- Decide whether to use name matching. By its very nature, matching on name is intrinsically unreliable because many people have the same names. If you use this feature, be sure to run your process in Test mode and review the results to be sure you agree with the matches.
- Decide which PI Person fields you want to update with the data from your input file by checking or unchecking options labeled “Change these fields for persons with a clean match”. If you leave all the options checked, all fields will be potentially updated. For Person Type and Folder Path you also have the ability to set a designated value for all the persons that match your input file records. The three options have the following effects:
- “Use PersonType column if valid value present in input” – Change each person’s PI data based on the value of the PersonType or FolderPath column in that person’s row of the input file.
- “Change to: (drop-down list)” – Change all persons’ PI data to this one value, ignoring whatever value is in the input file
- “Ignore” – Do not change this field at all in the PI data — ignore the input file column
- Perform some tests using Process Now
- You should run in Test Mode at first, then look at the Process Log file to see if the expected changes seem to be correct. There is no “undo” if you run in Live Mode, so be sure to check your Test Mode output carefully.
- You can limit the number of records to process in Test Mode using the Max Records to Process setting. For example, if you have a large input file, set this value to 2 or 10 when you first run and see if those PI persons are being handled correctly. Then increase the number and let it process the whole input file.
- Run your data in Live Mode using Process Now!
- Again, you might use a low number in Max Records to Process and then check the results to make sure you like them.
- Then run again with Max Records to Process set to 0 (zero) which means “no limit” to process all your input file data.
Optimizing your usage of the PI API:
- On your first use of the Sync process (after verifying in Test Mode, of course), possibly in partial batches, process all your person data so that every PI person will be updated to match your system of record.
- On subsequent uses of the Sync process, include only the person data you believe has changed since your first run (recent hires, recent terminations, name changes, assignment changes, etc).
- Periodically, include all person data again (like the first time) just to be sure everything is in sync.
Processing Results
Up to three output files are generated by the Sync process and placed into the Output Location specified in the Setup tab:
1. Sync Person Data Log File
When running the Sync process, a file named “{MagicTools or your file prefix}-SyncPersonDataLog-{Test or Live}-{DateTime}.csv” is created. It describes all that is known about the handling of each row of input data processed, in a comma-separated values format. In Test Mode, it describes the proposed changes, and in Live Mode it describes the actual changes.
Use this file to determine whether MagicTools is matching and changing as expected.
The first row contains column names.
The second row contains “Settings” in the RecordStatus column and the remaining columns contain information about the settings used to process the input data or remain blank. The MatchResult column indicates . The NewExternalID through NewJobName columns will also have values revealing the settings chosen at the time it was run that affect the type of changes to be performed.
The third and following rows contain the results of processing the Input file.
The columns and their possible values are:
- RecordStatus
- In the second line/row of each file the value Settings will appear – see note above
- Changed – a single record was found to match and one or more fields were changed using the input file
- NoChange – a single record was found to match but all the PI data already matched the input file
- SkipNoMatch – the record was skipped because no match was found using any of the available input columns
- SkipNoColumnsToMatch – the record was skipped because none of the match columns had values for that person
- SkipBadInput – the record was skipped because of a problem with an input field. See the FailureNote column for an explanation.
- MatchResult = a collection of one or several of the following, separated by colons (:)
- In the second line/row of each file this column will reveal whether First and Last Name are used for matching (MatchUsingFirstLast) or not (MatchWithoutFirstLast)
- OnePersonID, OneCurrExtID, OnePrevExtID, OneCurrEmail, OnePrevEmail – exactly one match!
- NoPersonID, NoCurrExtID, NoPrevExtID, NoCurrEmail – the data didn’t match anyone
- ManyCurrEmail, ManyPrevEmail, ManyFirstLast – too many matches found, so not treated as a match
- MatchPersonID = the PersonId of the matched person, if a match was found — assessmentUserId is another name for PersonID in the PI system
- PersonPageUrl = web link to PI Person page, if found (Note: the PersonID is part of this web link)
- CurrentEmail to ArchiveMe columns = the original input file column values using standard column names
- PIEmail to PIJobName columns = the original values in PI data for this person before any change
- NewEmail to ArchiveMe columns
- In the second line/row of each file, these columns will contain the settings used for each of these data items at the time the process was started. Possible values include:
- UseInputData – change the PI data using data from the input file
- DoNotChange – no change to the data item regardless of the input file
- UseFixedValue – the option was chosen to assign a single fixed value to all matched persons
- FolderPath – the one selected Folder
- PersonType – the one selected PersonType
- ArchiveMe – archive all persons (See also: Archive and Anonymize Defined)
- In all other lines, these columns contain the new values of any columns that were changed in PI; unchanged fields are empty
- In the second line/row of each file, these columns will contain the settings used for each of these data items at the time the process was started. Possible values include:
- FailureNote – if a person is skipped or if an update of PI data fails, additional info will be shared here to help you determine what went wrong
2. Skipped Records File
If any input file rows are skipped as described above, the Sync process will generate a file named “{MagicTools or your file prefix}-SyncPersonDataSkipped-{Test or Live}-{DateTime}.csv”:
- Format: comma-separated-values (CSV) file, ready to be used as input for a re-run after you’ve tried to fix the problems
- Each time you run the process and some records are skipped, another Skipped Records file will be generated
- If you chose the multiple match option: Skip without update and log all matching records, additional rows will appear in the Skipped records file below all rows from the input file that had multiple matches.
- RecordStatus column:
- OrigInput – this row is directly taken from the original input file and will show the match outcome
- PossibleMatch – this row is one of the matches to the previous OrigInput row
- MatchResult column:
- For OrigInput rows – this column will tell what happened with the matching logic. For example, “NoCurrEmail:NoPrevEmail:NoFirstLast:ManyOtherFirstLast:2” means that no matches were found using current email, previous email, or first and last name, but 2 matches were found using Other First or Other Last names.
- For PossibleMatch rows – this column will show a numbered description of what data was used to produce multiple matches
- Email Match 01, Email Match 02, etc
- Name Match 01, etc
- Note column – for the OrigInput rows, a line of instructions appear, “Possible matches below. To choose a match set Note = ‘Match’. To remove set ArchiveMe = ‘Archive’ or ‘A'”
- Note = Match – This action, if taken, will not be automatically processed by MagicTools when used as input. This is merely a way of marking rows that require some kind of manual action either in the PI data or in the Skipped file to prepare for another Sync process.
- ArchiveMe = Archive – this action, if taken, will be automatically processed by MagicTools when used as Sync input, but you should perform a Sync action with ONLY ArchiveMe settings chosen before re-processing the other records in the Skipped file. By archiving the wrong matches that you wish to throw away, the matching process may find only one match and treat that as success.
- RecordStatus column:
What to do with the Skipped Records File:
- If persons were skipped because more than one match was found, you may wish to use the MagicTools Clean processes to remove duplicate persons, then run the skipped file as input to the Sync process.
- Skipped persons may require manual fixes in the Skipped records file or in the PI software before running the Sync process again. For example:
- If a person in your input file is found to have multiple PI person records that match:
- If you chose the option to log all matches, you will see rows in the Skipped records file for each match. You can use the information in these rows to update the original input data row in the Skipped records file after you decide which person, if any, you would like to treat as a match.
- If you wish to look at person data directly in PI, you may need to go into PI software, decide which one of the possible matches is “best”, and manually update the right one and/or archive the others using the PI software features.
- If your input file contained an invalid Job Name or Folder Path, you may need to fix the value in the input file to match a folder or job that is actually available in your PI data.
- If a person in your input file is found to have multiple PI person records that match:
- After doing some form of clean-up of the PI data, run the Sync process again using either the original input file or a fixed version of the Skipped Records file to process only the persons who were skipped the previous time.